
Conteneurs, conteneurs, conteneurs, conteneurs. J’entends ce mot plus que mon nom ces jours-ci, qu’est-ce qu’ils ont de si spécial, est-ce de la magie, un savoir ou juste une boule ?
C’est ce à quoi je vais essayer de répondre dans cette série d’articles.
Pour rendre le sujet plus simple et moins ennuyeux, il sera divisé en plusieurs articles, dont les principaux sujets sont :
Dans tous les articles, nous ne nous en tiendrons pas à l’aspect théorique de chaque thème, je crois que pour bien comprendre un sujet, il faut aller sous le capot et tout faire soi-même, et c’est ce que nous allons essayer de faire dans chaque section. De quoi ai-je besoin ?
Dans cette série d’article vous aurez besoin de 2 VMs Linux avec une distribution de votre choix, je vais utiliser une distribution Ubuntu 20.04.
C’est parti !
Un conteneur est un processus, attendez, où allez-vous, nous n’avons pas encore fini. Où en étions-nous, ah oui, un conteneur est un processus mais un processus spécial, pourquoi spécial, nous allons le découvrir. Mais avant de comprendre ce qui le rend si spécial, allons faire un tour au Kernel Land.
Comme vous le savez bien ou pas. Dans la mémoire Linux, nous avons deux espaces où les applications s’exécutent généralement, l’espace noyau et l’espace utilisateur. L’espace noyau est protégé et seul le code noyau est autorisé à y accéder. D’autre part, l’espace utilisateur peut être utilisé par des applications non privilégiées, comme un navigateur ou un éditeur de texte.

Donc si l’espace utilisateur ne peut pas accéder à l’espace noyau, comment une application de l’espace utilisateur peut-elle ouvrir un fichier situé sur un disque ou envoyer un ping ?
La réponse est les appels système. Les appels système sont utilisés par les applications de l’espace utilisateur pour demander au noyau de faire quelque chose, comme ouvrir un fichier, envoyer un paquet réseau ou créer un nouveau processus.

Ainsi, comme nous pouvons le voir, un processus s’exécutant en espace utilisateur demande au noyau de multiples actions pendant son exécution, mais cela n’explique pas comment un processus peut être créé.
Comment les processus sont-ils créés ?
Chaque processus est un fork d’un autre processus, pour ceux qui ne savent pas ce qu’est un fork. Fork est encore un autre appel système, ce appel système peut être appelé par des processus (parents) qui s’exécutent dans l’espace utilisateur pour créer de nouveaux processus (enfants).
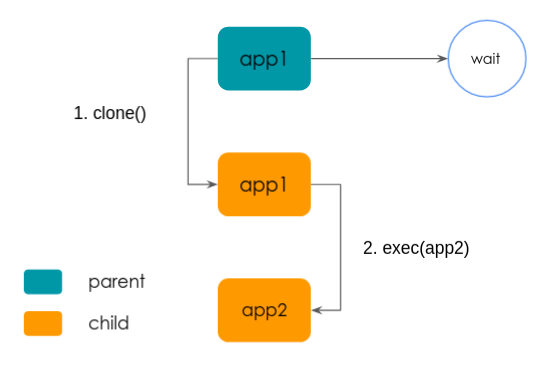
Chaque processus est créé comme dans le diagramme ci-dessus :
1. Le processus parent appelle le clone syscal, avec quelques flags le kernel va copier la zone mémoire de app1, à cet état l’enfant et le père auront le même code à exécuter. Par exemple lorsque vous exécutez dans votre bash la commande ls, à cette phase l’enfant pointe toujours vers le code bash.
2. Pour charger le code de l’app2, l’appel système exec va charger le code de l’app2. Si nous continuons avec le même exemple que dans la phase 1, avec ce appel système le code ls est chargé.
Note:
Certains d’entre vous connaissent l’appel système fork comme le moyen de créer de nouveaux processus. Pour clarifier, l’appel système clone est le nouveau fork, il fait le même travail mais permet plus de contrôle sur le contexte d’exécution d’un processus. Maintenant, la fonction forks de la glibc appelle l’appel système clone avec des drapeaux qui fournissent le même effet que l’appel système fork traditionnel. Mais vous n’avez pas besoin de connaître ces détails ennuyeux.
Nous savons maintenant comment un processus est créé, mais qu’est-ce qui rend un conteneur si spécial par rapport à un processus normal La différence est qu’un conteneur est un processus isolé du reste des autres processus, cette isolation peut être à un ou plusieurs niveaux, certaines des isolations bien connues sont au niveau réseau, montage des fichiers, l’IPC (Inter Process Communication), PID et ainsi de suite. Mais qu’est-ce qui rend cette isolation possible ? La réponse est le noyau, qui utilise la fonctionnalité Namespace.
Donc, qu’est-ce qui va changer si on refait le même schéma

Comme nous pouvons le voir, la procédure est la même, la différence réside dans les flags passés à l’appel système clone, certains de ces flags sont utilisés pour créer de nouveaux espaces de noms :
Clone n’est pas le seul appel système utilisé pour isoler un processus, il y a d’autres appels système aussi :
Maintenant, le diable qui se cache derrière les conteneurs est dévoilé, pour le noyau les conteneurs n’existent pas, c’est tout un tas de namespaces qui isolent le processus comme dans le film inception où l’acteur pense qu’il est dans le monde réel mais au lieu de cela il est dans un rêve, et nous n’allons pas parler du niveau deux inception (conteneurs dans un conteneur), ce qui est possible aussi avec les namespaces.
En fin de compte, je pense que le tweet de Jérôme Petazzoni résume bien la situation.
« Containers are processes,born from tarballs,anchored to namespaces,controlled by cgroups »💯@alicegoldfuss #VelocityConf
Dans le prochain article, nous utiliserons les notions que nous avons vues aujourd’hui pour créer un conteneur à partir de rien, ce n’est pas si difficile, vous verrez, à la prochaine fois.